¿Por qué huelen los code smells?
Hace unas semanas acudí a la PulpoCon 23 y me gustó mucho una ponencia por Nino Dafonte en la que entre muchas cosas explicaba por qué los code smells son code smells. A estas alturas casi todos ya conocemos los code smells más habituales y reconocemos los problemas que pueden traer consigo, ¿pero sabemos realmente por qué son tan perniciosos?
La clave está en entender como funciona nuestro cerebro cuando se enfrenta a un problema. Según Felienne Hermans (The programmer’s Brain) nuestro cerebro utiliza tres tipos de memoria para resolver un problema, tenemos la memoria a corto plazo, la memoria a largo plazo y la memoria de trabajo. En la memoria a largo plazo es donde encontramos nuestro conocimiento basado en la experiencia, es la primera memoria que usamos para resolver un problema, ya que en ella encontramos las herramientas con las que nos encontramos más cómodos por tener familiaridad con ellas. En la memoria a corto plazo es donde almacenamos la nueva información que se nos presenta, esta memoria tiene muy poca capacidad y si intentamos meter demasiados conceptos en ella notaremos que algunos se “caen”. Finalmente, tenemos la memoria de trabajo, que es el espacio que usamos para razonar, mezclando información de nuestras memorias a corto y largo plazo.
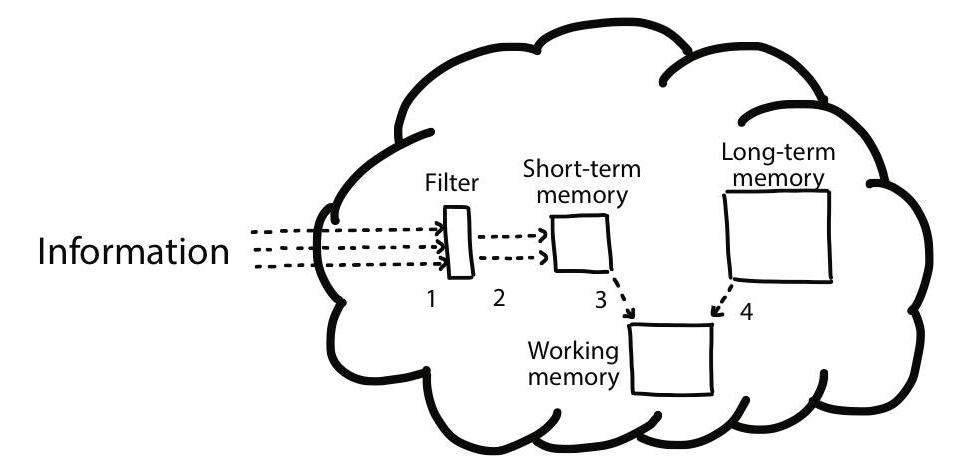
Cuando leemos un trozo de código, o cualquier otro tipo de problema que se nos presente, hacemos pasar la información que captamos por un filtro, la función del filtro es determinar si el tipo de problema nos es conocido en función de nuestra memoria a largo plazo. Luego introduciremos los detalles del problema en la memoria a corto plazo y usaremos la memoria de trabajo para unir nuestra experiencia con los detalles y razonar sobre ello.
Veamos este sencillo ejemplo de código Java:
public class BinaryCalculator {
public static void main(Integer n) {
System.out.println(Integer.toBinaryString(n));
}
}
Si el lector es un programador de Java experimentado en seguida habrá reconocido la declaración de la clase y del método main como boilerplate necesario de Java, pero que no nos da ninguna información sobre la intención del programa. Su mente se habrá enfocado en seguida en donde se encuentra la información relevante, y la habrá convertido en algo que mentalmente sería como print Integer.toBinaryString(n). Esto sucede porque su memoria a largo plazo le ha permitido reconocer un patrón por el cual ella ya sabía que las primeras líneas no le aportaban nada o casi nada y ha sabido que el contenido de valor para entender que hace este código se encontraba únicamente en la línea 3.
En cambio, si el lector no es un programador habituado a Java, habrá leído cuidadosamente el código, usando su memoria de trabajo para mapear los conceptos que le son familiares (class, visibilidad, argumentos de la función) con elementos de su memoria a largo plazo que le ayudan a entender el código, posiblemente creando una imagen mental del mismo código en un lenguaje con el que se siente más familiarizado.
Tipos de sufrimiento cuando leemos código
Falta de conocimiento
A no ser que seas matemático o tengas conocimientos de matemáticas por encima de lo “básico”, la siguiente expresión te dice tanto como un poema en sánscrito.

Esto es un ejemplo de sufrimiento causado por falta de conocimiento, tu memoria a largo plazo no tiene las herramientas para entender este problema.
Falta de capacidad de proceso
Veamos un ejemplo de código en BASIC:
05 REM some piece of code
10 HOME: TEXT
20 LET A = 1071 : LET B = 462
30 IF A < B THEN C = A : A=B : B=C
40 PRINT A,B
50 LET C = A - INT(A/B)*B : REM C = A MOD B (A modulo B)
60 LET A = B : B = C
70 IF B > 0 GOTO 40
80 PRINT "GCG is "; A
90 END
En este caso el sufrimiento viene dado por la dificultad de ordenar en la cabeza todo lo que está sucediendo en este código. El código simplemente está buscando el máximo común divisor entre dos números, pero la falta de abstracciones hace que resulte difícil razonar con este código.
Limitaciones de la memoria a corto plazo
Finalmente, tenemos el sufrimiento causado por la limitación de la memoria a corto plazo, aquí encontramos típicos smells como las funciones con demasiados argumentos, los métodos muy largos, las clases con demasiadas responsabilidades, etc.
Nuestra memoria a corto plazo puede gestionar un número limitado de conceptos, cuando mezclamos demasiadas cosas empezamos a perder información, sin embargo, hay un truco para “hackear” esta limitación, que consiste en usar abstracciones. Cuando encapsulamos bien diferentes aspectos de nuestro código en encapsulaciones correctamente definidas, somos capaces de intercambiar los múltiples detalles que implica un “algo” por su respectiva abstracción, de esta manera algo que ocupaba múltiples “slots” en nuestra memoria a corto plazo pasa a ocupar un solo “slot”.
Créditos
El crédito a quien es debido, gracias Nino Dafonte por tu presentación en la PulpoCon, dejo un link a sus slides. Su presentación está, en parte, inspirada por el libro The programmer’s Brain de la editorial Manning.
Finalmente, os dejo con una presentación de la autora del libro en la que habla de las tres memorias.